
These are my notes summarizing the 1st chapter of the book “Designing Data-Intensive Applications.” It's a great book that I highly recommend for any engineer with a couple years of experience looking to better understand how to design great systems. A preview of the entire first chapter is available as well (paid link).
Here are the five common app components to help us build data-intensive apps:
- Database - Store data so other apps can find & use it later.
- Cache - “Remember” the result of expensive operations, to increase the speed of read/get operations.
- Search Index - Enable keyword search or search filters.
- Stream Processing - Send messages to other processes to be handled asynchronously.
- Batch Processing - Crunch large data jobs in the background.
The 3 main concerns for making good systems: reliability, scalability, and maintainability.

...All three are important, but the order matters. Neither scalability nor maintainability are important if your system isn't reliable. Let's dive into each one!
Reliability
A reliable system:
- performs the expected function.
- performs speedily enough to complete its function.
- tolerates, handles, or recovers-from errors or faults.
- prevents unauthorized access or abuse.
Scalability
- Can the system handle changes in load?
- Scaling requirements change over time. A reliable system under today’s load might no longer be reliable under tomorrow’s load.
- Scale isn’t black/white. Systems scale in different ways & to different degrees...
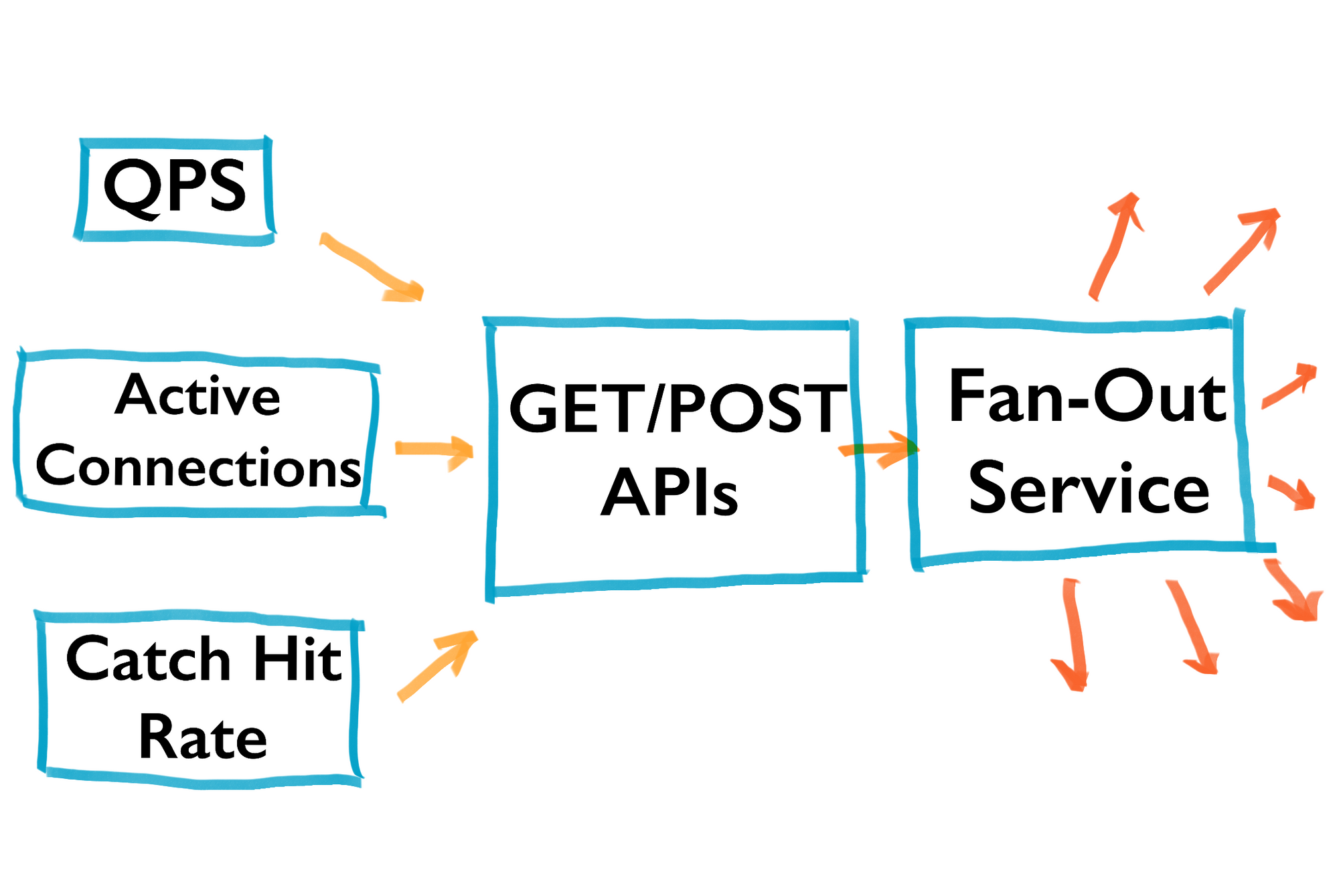
- Calculate “actual system load,” not just the input load. For example, in a system like Twitter, the fan-out service may incur more actual system load than the inputs.
- Identify the average load, peak load, and possible future loads...then determine the system’s performance for each.
- Look at each load parameter —> does increasing it have a large effect on performance? How much?
- When measuring API performance, use percentiles not averages. It’s good to know how many customers are getting slow responses, rather than only looking at the imaginary “avg” customer’s experience.
- Look at the slowest systems calls / operations, especially when analyzing a page/action that requires all to complete before proceeding (because the user is blocked by this limiting factor).
- Elastic systems scale-out in an automated fashion. Manual scaling is simpler, causes fewer “surprises” from changes, and produces less “thrashing.”
Scaling Playbook
if (stateless) —> scale-out
if (stateful) —> scale-up until you can’t
Designing a system that scales well is very specific to each situation - that’s why we need to ask the right questions, gather the right requirements, and make good assumptions back of the envelope estimations).
Maintainability
Why spend the effort to make systems maintainable? Because on-going costs are much greater than initial development costs. Always.
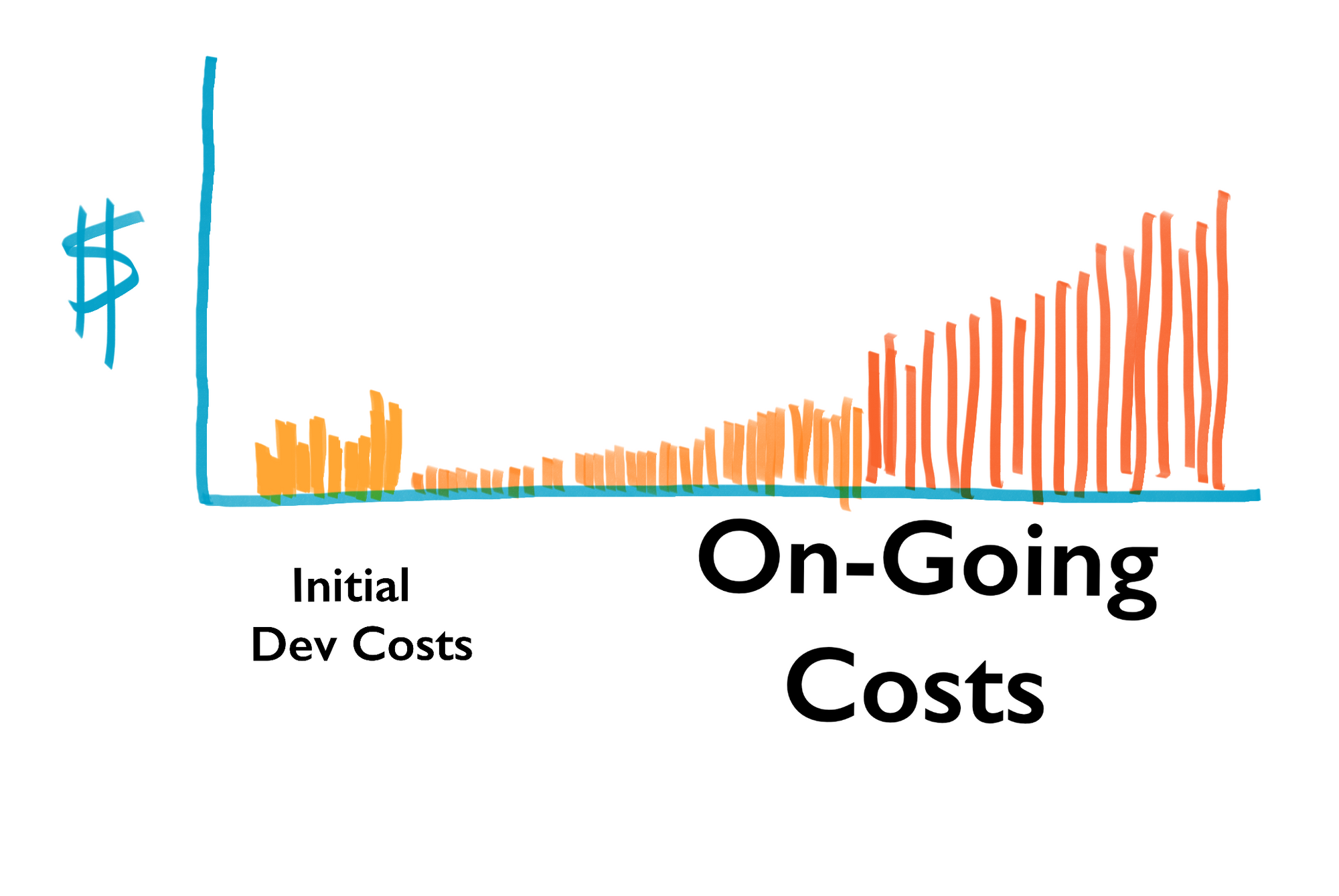
Systems require constant work. Bugs, continuous operations, investigating failures, adapting to new tech, adding new features, reducing tech debt...all these things demand that other engineers be able to understand your system and make changes.
How do we make systems maintainable?
- Operability - Make routine operations easy. Is it easy to keep it running?
- Simplicity - Manage complexity. Is it easy for new developers to join and contribute to the system?
- Evolvability - Make change easy. Is it easy for changes to be made to meet new requirements, fix unexpected bugs, and/or handle new system load? These kinds changes will often be unexpected, and can’t be planned for in advance.
More on Operability
What kind of stuff should be considered “routine”?
- Logging / observability
- Deployments
- Automation support
- Updates / patches
- Documentation
- Configuration changes
- Restoring from a bad state
More on Simplicity
- As a project proceeds, complexity ⬆️ and productivity ⬇️
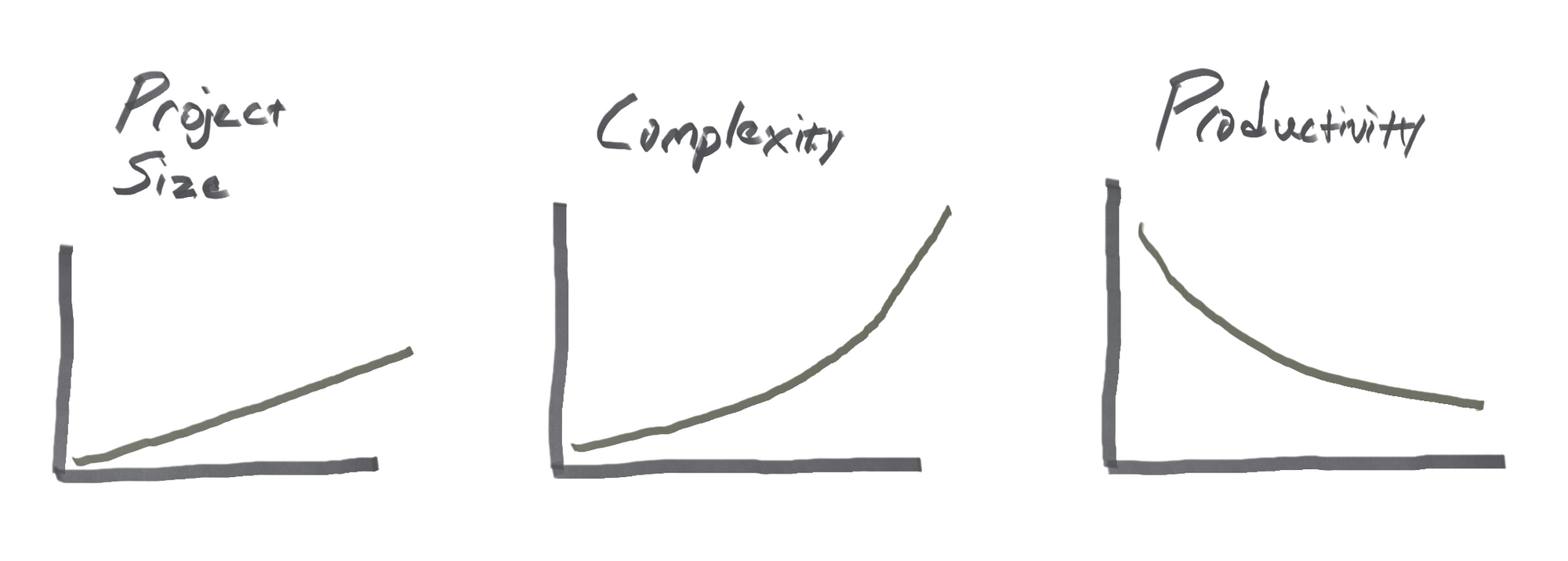
- Complexity increases exponentially even when project size grows linearly.
- Potential causes of complexity (there are many): hacks, “one-off” code changes, spaghetti code (tangled dependencies), tight-coupling, etc.
- Using abstractions (like the DRY pattern) can be a great way to reduce complexity. But it can also create more at times. Sometimes the KISS pattern work well, and sometimes those two patterns are at odds.
- Complexity is “accidental” if its cause isn’t the problem-space, but your implementation. Knowing the difference can help you target and remove the latter!
More on Evolvability
- Requirements change often, and for a variety of reasons, so be agile.
- Don't try too hard to anticipate or guess what future changes will be needed. The biggest challenges are almost always unpredictable.
Learn how to do large migrations for large systems. Practice by reviewing what other tech companies have done. Some examples:
- Twitter infrastructure that allows them to scale
- Stripe's Online migrations at scale
- Stripe's move from Flow to Typescript
Final thought
There’s no silver bullet for designing systems to be reliable, scalable, and maintainable. But there are patterns, and the rest of this book is spent exploring those patterns. Highly recommend picking up a copy if you want to learn more (paid link).

